import sys
input = sys.stdin.readline
sys.setrecursionlimit(10**5)
from collections import deque
# 세로와 가로 칸 개수
r, c = map(int,input().split())
# 지나갔던 알파벳 정보 배열
alpha = [0]*26
result = 0
count_list = [[1]*c for _ in range(r)]
visited = [[False]*c for _ in range(r)]
area = [[0]*c for _ in range(r)]
for i in range(r):
area[i] = (list(input()))
def dfs(x,y):
global result
if x < 0 or x >= r or y < 0 or y >= c or visited[x][y]:
return False
visited[x][y] = True
alpha[ord(area[x][y])-65] = 1
nx = [-1,1,0,0]
ny = [0,0,-1,1]
for i in range(4):
temp_x = x + nx[i]
temp_y = y + ny[i]
if temp_x >= 0 and temp_x < r and temp_y >= 0 and temp_y < c:
if not visited[temp_x][temp_y] and alpha[ord(area[temp_x][temp_y]) - 65] == 0:
count_list[temp_x][temp_y] = count_list[x][y] + 1
dfs(temp_x,temp_y)
if count_list[x][y] > result:
result = count_list[x][y]
visited[x][y] = False
alpha[ord(area[x][y])-65] = 0
dfs(0,0)
print(result)이번 문제는 알파벳이 저장된 배열에서 상-하-좌-우로 이동하되, 이전에 만난 알파벳이 적힌 칸은 이동할 수 없다는 가정하에 최대로 지날 수 있는 칸수를 구하는 문제이다.
처음에는 이 문제를 BFS를 사용하여 풀이하려고 했지만, 가장 중요한 문제점은 한 영역을 탐색하고 나서 방문 처리를 해버리면 다른 경로로 탐색하려고 했을 때 해당 영역을 탐색할 수 없고, 한 경로에서 만났던 알파벳을 초기화해 주지 않으면 다른 경로에서 경로를 탐색하는데 영향을 받는다는 것이었다.
def dfs(x,y):
global result
if x < 0 or x >= r or y < 0 or y >= c or visited[x][y]:
return False
visited[x][y] = True
alpha[ord(area[x][y])-65] = 1
nx = [-1,1,0,0]
ny = [0,0,-1,1]
for i in range(4):
temp_x = x + nx[i]
temp_y = y + ny[i]
if temp_x >= 0 and temp_x < r and temp_y >= 0 and temp_y < c:
if not visited[temp_x][temp_y] and alpha[ord(area[temp_x][temp_y]) - 65] == 0:
count_list[temp_x][temp_y] = count_list[x][y] + 1
dfs(temp_x,temp_y)
if count_list[x][y] > result:
result = count_list[x][y]
visited[x][y] = False
alpha[ord(area[x][y])-65] = 0따라서 이러한 문제점을 해결해주기 위해 재귀함수를 사용한 'DFS 알고리즘'과, 탐색하고 난 뒤에 다른 경로가 이전의 탐색경로에 영향을 받지 않도록 원상복구 시켜주는 '백트래킹(Backtracking) 기법'을 사용해주었다 !
visited[x][y] = True
alpha[ord(area[x][y])-65] = 1위 코드를 보면, DFS 함수 시작시에 방문 여부를 확인해주는 배열(visited)과 알파벳 접근 여부를 확인해주는 배열(alpha)을 방문 처리해주었다.
visited[x][y] = False
alpha[ord(area[x][y])-65] = 0그리고 마지막에 for문을 통한 DFS 재귀가 끝나고 나면(탐색이 최종적으로 끝났을 때) 방문 처리와 알파벳 접근 여부를 원상복구(Backtracking)시켜주었다.
여기까지는 DFS 알고리즘과 백트래킹을 자연스럽게 생각한다면 구현할 수 있는 내용들이었다.
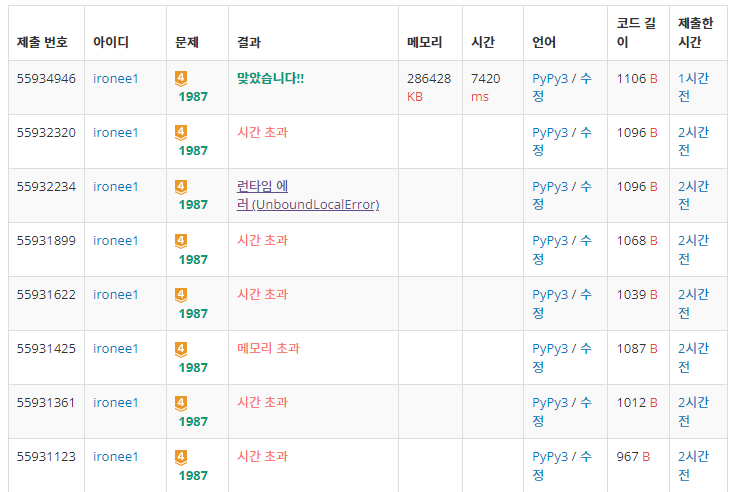
하지만 진짜 난관은 바로 "시간 초과" 였다. 분명 로직은 완벽하다고 생각했는데, 자꾸 백준에서 채점할 때마다 시간초과가 발생하였다.
시간 초과를 어떻게 해결했는가 ?
파이썬으로 알고리즘 문제를 풀었을 경우 시간초과를 해결해줄 만한 방법들은 여러가지가 있다.
https://dailylifeofdeveloper.tistory.com/182
[Python] 시간 초과 날때 해결방법!
안녕하세요! daily_D 입니다! 👩🏻💻 오늘은 Python 으로 문제풀이할 때 시간초과가 나는 경우 해결할 수 있는 몇가지 방법을 알려드릴까합니다! 1. sys.stdin.readline()로 입력받기 입력값을 받아 저
dailylifeofdeveloper.tistory.com
위 블로그를 참고하여 input() 대신 sys.stdin.readline()을 사용한다던지, sys.setrecursionlimit(n)을 설정해준다던지 몇 가지 방법을 동원했는데도 시간초과가 발생하여 내 코드를 보고 시간이 불필요하게 많이 소요되는 부분을 찾아보기로 했다.
# 지나갔던 알파벳 정보 배열
alpha = []
...
visited[x][y] = True
alpha.append(area[x][y])
...
if temp_x >= 0 and temp_x < r and temp_y >= 0 and temp_y < c:
if not visited[temp_x][temp_y] and (area[temp_x][temp_y] not in alpha):
count_list[temp_x][temp_y] = count_list[x][y] + 1
dfs(temp_x,temp_y)
...
visited[x][y] = False
alpha.remove(area[x][y])위 코드는 본인이 시간초과가 발생했을 당시의 코드인데, 문제점은 바로 '알파벳을 접근했는지 여부를 확인하는 방식'이었다.
1. 위 코드를 보면 본인은 DFS로 처음에 경로를 이동할 때 마다 알파벳을 alpha 라는 리스트에 추가(append) 해주고,
=> O(1)
2. 알파벳을 접근했었는지 확인하기 위하여 조건문에서 in 연산자를 사용하여 alpha 리스트 내에 알파벳이 존재하는지 탐색해주었으며,
=> O(N)
3. 백트래킹을 위해 알파벳을 지울 때도 remove 함수를 사용하여 삭제를 해주었다.
=> O(N)
이 3가지가 시간초과를 발생시킨 원인들이었다.
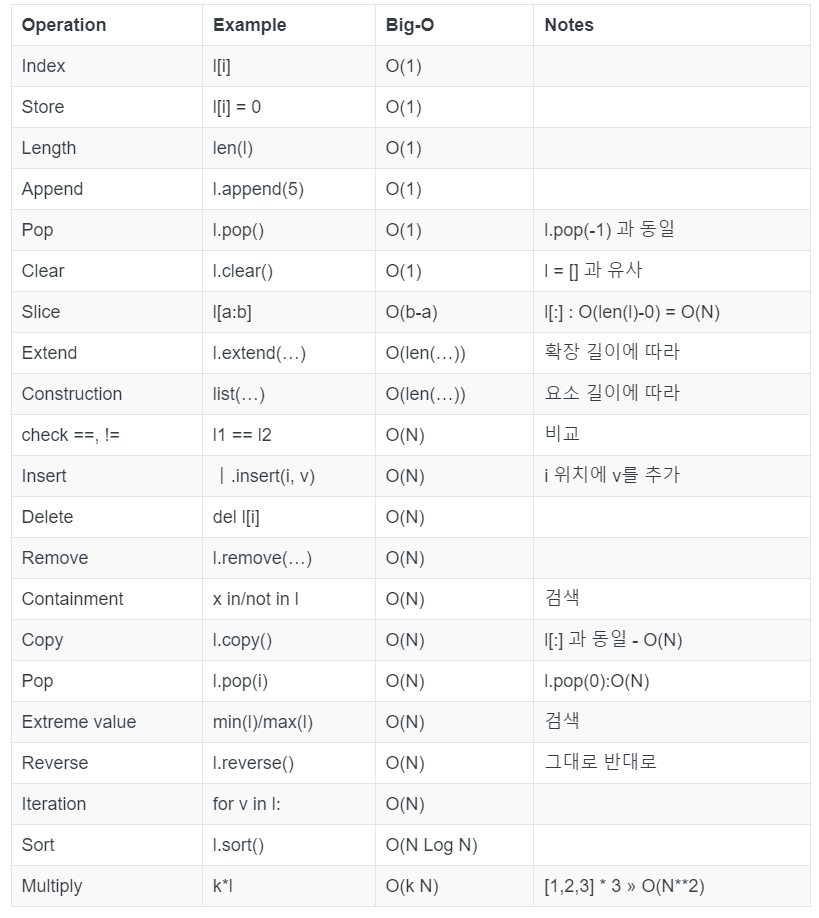
append 함수는 리스트를 순회할 필요가 없기 때문에 시간복잡도가 O(1)이지만, in 연산자나 remove 함수와 같은 경우에는 리스트를 순회해보아야 하기 때문에 시간복잡도가 O(N) 이다.
# 지나갔던 알파벳 정보 배열
alpha = [0]*26
...
alpha[ord(area[x][y])-65] = 1
...
if temp_x >= 0 and temp_x < r and temp_y >= 0 and temp_y < c:
if not visited[temp_x][temp_y] and alpha[ord(area[temp_x][temp_y]) - 65] == 0:
count_list[temp_x][temp_y] = count_list[x][y] + 1
dfs(temp_x,temp_y)
...
if count_list[x][y] > result:
result = count_list[x][y]
visited[x][y] = False
alpha[ord(area[x][y])-65] = 0따라서 이러한 시간복잡도가 높은 작업들을 최소화하기 위하여 사용한 방식이 바로 알파벳 26개의 접근 여부를 저장하는 Hash Table을 만드는 것이었다 !
알파벳 대문자는 총 26개로 정해져있기 때문에, A-Z를 인덱스 0~25로 저장할 수 있는 리스트(alpha)를 먼저 만들어준 뒤에 ord() 함수를 사용하여 문자를 10진수로 변환해주면서 접근 여부를 저장해준다면 시간복잡도 O(1)으로 같은 동작을 이끌어낼 수 있다 :)
이 외에도 2차원 배열을 area = [] 로 선언하고 append 하는 방식에서 미리 2차원 리스트를 선언해주는 방식으로 개선시켜줬는데, 이번 문제를 통해 배운 점은 다음과 같이 정리할 수 있다.
특정한 자료구조의 범위가 주어진 상황에서는 사전에 범위에 맞게 자료구조를 초기화해두고 인덱스에 접근하거나 입력을 받으면 시간복잡도를 최소화 할 수 있다.
'Algorithm > DFS' 카테고리의 다른 글
| [백준 11725번] 트리의 부모 찾기 (0) | 2023.04.06 |
|---|---|
| [백준 14503번] 로봇 청소기 (0) | 2023.02.17 |
| [백준 4963번] 섬의 개수 (0) | 2023.02.15 |
| [백준 11724번] 연결 요소의 개수 (0) | 2023.02.15 |
| [백준 1012번] 유기농 배추 (0) | 2023.02.13 |